Recently I switched my search code to Annoy because the input dataset is huge (7.5mil records with 20k dictionary count). It wasn’t without issues though, however I would probably talk about it next time. In order to figure out what each parameters meant, I spent some time watching through the talk given by the author @fulhack.
The idea was simple enough, though it still feels like magic to me. Out of curiousity, I spent some time partially implementing the algorithm in 2D. There are parts I don’t quite understand, for instance how to prioritize which tree to be used (This is what separates rockstar engineer and a n00bie like me). I can’t read C++, so the code I am showing below is completely my own (which is why it is not optimized unlike the original library). Also the code only works for point in 2D, simply because this is just a toy for learning.
The most important part is the tree building, which is shown in the code below.
from random import sample, randint, random
from math import floor, pow, fabs, sqrt
from uuid import uuid4
from numpy import argmin
import matplotlib.pyplot as plt
from itertools import chain
import time
def middle(points):
return (points[0][0] + points[1][0]) / 2, (points[0][1] + points[1][1]) / 2
def m(points):
return (points[1][1] - points[0][1]) / (points[1][0] - points[0][0])
def normal(_middle, _m):
normal_m = -pow(_m, -1)
def _(point):
y = normal_m * (point[0] - _middle[0]) + _middle[1]
return point[1] - y
return _
def split_points(points):
result = sample(points, 1)
while(True):
point_b = sample(points, 1)[0]
if point_b[0] - result[0][0] != 0 and point_b[1] - result[0][1] != 0:
result.append(point_b)
break
return result
def tree(points):
result = {}
if len(points) <= 5:
result = {
'type': 'leaf',
'count': len(points),
'uuid': uuid4(),
'children': points
}
else:
split = split_points(points)
branching_func = normal(middle(split), m(split))
positive = []
negative = []
for point in points:
if branching_func(point) > 0:
positive.append(point)
else:
negative.append(point)
result = {
'type': 'branch',
'func': branching_func,
'count': len(points),
'uuid': uuid4(),
'children': [tree(negative), tree(positive)]
}
return result
So the implementation follows the slide as much as possible. I first randomly pick two points, then I find a perpendicular line in between it to separate all the points. For obvious reason I didn’t select points that ended up being a horizontal / vertical line (parallel to x or y axis). Points that lie on either side of the line will be grouped separately. Keep repeating the process, until the remaining points is no more than 5.

The generated clusters. Each color represents a cluster.
While writing the code above, I did some quick revision to linear algebra because I wasn’t quite sure how to get the slope value (m). I am quite happy with the end product (though it could really use some optimization).
So now that building a tree is possible, next is to attempt searching.
def distance(alpha, beta):
return sqrt(pow(alpha[0] - beta[0], 2) + pow(alpha[1] - beta[1], 2))
def leaves_nearest(point, tree, threshold):
result = []
if tree['type'] == 'leaf':
result.append(tree)
else:
delta = tree['func'](point)
if delta > 0:
result = leaves_nearest(point, tree['children'][1], threshold)
elif fabs(delta) <= threshold:
result = leaves_nearest(point, tree['children'][0], threshold) + leaves_nearest(point, tree['children'][1], threshold)
else:
result = leaves_nearest(point, tree['children'][0], threshold)
return result
def search_tree(query, nleaves):
candidates = list(chain.from_iterable([leaf['children'] for leaf in nleaves]))
distances = [distance(query, point) for point in candidates]
idx_min = argmin(distances)
return (distances[idx_min], candidates[idx_min])
The way searching works is to first find leaf nodes (I am bad in using the right term to describe things) containing only points that is nearest to the query point. We do this by following the tree hierarchy, by feeding the point to the branching function. However, it is still possible to have the closest point being assigned to another leaf node. In order to handle that case, I added a threshold parameter, so that if the query point lies slightly below the line, then it passes the check too. Therefore, instead of getting just one leaf node (where the query point is located), it is possible to get a number of neighbouring nodes too.
By using this method, instead of comparing the query point to every point in the space, I only need to compare probably just tens of them (depending on how generous I am on the threshold). For comparison purpose, I also wrote a brutal search function.
def search_brute(query, points):
distances = [distance(query, point) for point in points]
idx_min = argmin(distances)
return (distances[idx_min], points[idx_min])
So finally a quick comparison.
points = []
print('Generating Points')
for _ in range(10000):
points.append(tuple([randint(0, 999) for __ in range(2)]))
print('Building Tree')
_tree = tree(points)
from pprint import pprint
query = tuple([randint(0, 999) for __ in range(2)])
print('Given Query {}'.format(query))
print('Cluster Answer')
t0 = time.clock()
nleaves = leaves_nearest(query, _tree, 250)
canswer = search_tree(query, nleaves)
print('Search took {} seconds'.format(time.clock() - t0))
pprint(canswer)
print('Global Answer')
t0 = time.clock()
ganswer = search_brute(query, points)
print('Search took {} seconds'.format(time.clock() - t0))
pprint(ganswer)
And the output
Though I needed to traverse the tree to find the leaf nodes before doing actual comparison, but the whole search process is still close to 13 times faster. I am very impressed indeed. Even though my re-implementation is not a faithful 100% port, but I think I know why Annoy is so fast.
One thing I could do better, besides optimizing the code, is probably the threshold part. I should have measured the closest distance from a point to the line instead of calculating how far the point is below the line. However, I am already quite happy with the result. Just a quick visualization on how cool it is.
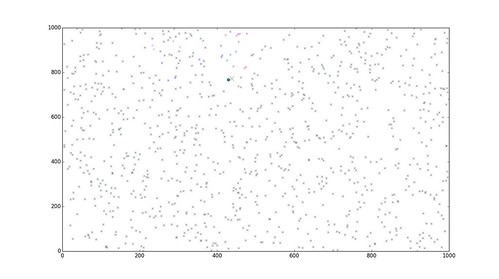
Search result
The query point is denoted by the filled circle. Then the larger cross (X) is the nearest point to the query point. Points that are considered as neighbours to the query points are colour-coded. Each colour represents a cluster. For clarity purposes, points from other irrelevant clusters are in same colour (sorry for my mixed spelling of color/colour throughout the post).
The idea can possibly apply to problems in larger dimensions beyond 2D, but I probably will just stop here.
