Often times, I am dealing with JSONL files, though panda’s DataFrame is great (and blaze to certain extend), however it is offering too much for the job. Most of the received data is in the form of structured text and I do all sorts of work with them. For example checking for consistency, doing replace based on values of other columns, stripping whitespace etc.
While a DataFrame could do most of the tasks mentioned above, it is really not a good way to do that. For example, I needed to do some horrible hacks to make some of the work done concurrently. In the end, DataFrame is really optimized for operations involving columns, not rows.
While my entire prototype was built around DataFrame (weird mix of blaze and panda’s implementation), I came across dask (also done by Continuum, which made blaze) while trying to see if dask.dataframe works better. Then I discovered dask.bag and I gave it a try. I kind of like the simplicity.
For instance, suppose I want to manipulate a large list. Given a list, I want to first replace each of them with a list of random number of size 5. Then each of the random number would be multiplied with another random number. Next zip the list with a tuple ('lorem', 'ipsum', 'dolor', 'sit') to become a dictionary. Then sum up all the values of 'dolor'.
The easiest solution is to write a for loop and wait until you are bored to death for the result. Or you could also do some magic with concurrent.futures.ThreadPoolExecutor/ProcessPoolExecutor which may or may not be maintained easily in the future. While running the code you wrote with either case mentioned, you may also be plagued with memory issues due to the sheer size of input list.
The alternative would be writing the manipulation with dask.bag, as follows.
import dask.bag as db
from dask.dot import dot_graph
import random
import json
bag = db.from_sequence(range(int(1e7)), int(1e6)) \
.map(lambda _: [random.random()] * 5) \
.map(lambda x: [item * random.random() for item in x]) \
.map(lambda x: dict(zip(('lorem', 'ipsum', 'dolor', 'sit', 'amet'), x))) \
.pluck('dolor') \
.sum()
print(bag.compute())
So my computer survived, and returned me an answer for this nonsensical fictional task. To figure out what happened, we can export a graphviz flow diagram to have an idea of what happened behind the scene.
dot_graph(bag.dask)
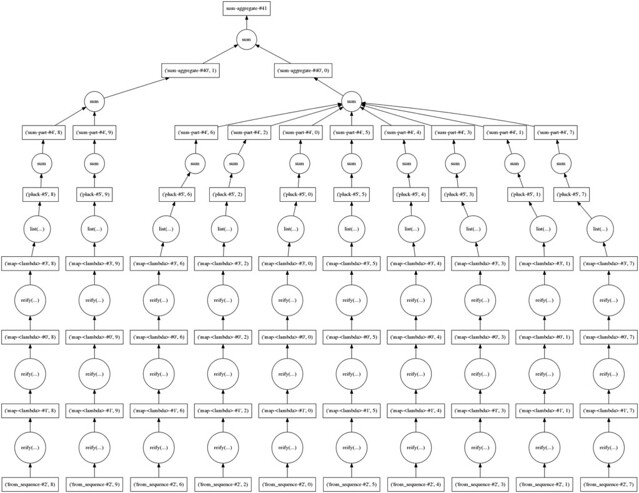
Quick visualization of the computation
So the computation split the input into 10 chunks as defined in the from_sequence() call. Then when a sum() is needed internally dask.bag runs a series of reduce operations to eventually get the total. Practically, from what I know so far is that, dask.bag builds the computation plan before actually executing it. Hence if I did not do the .compute() call there would be no computation actually takes place.
So back to the real world problem that I am facing. Now that we know dask.bag is awesome and helps in producing work that runs concurrently, the question is how to apply it in my problem. Practically I am given a JSONL file, with millions of objects. I need to process each of the object received from stdin, and output them back to stdout to be consumed by the next script.
The problem with delaying the computation until we’re set is that it swallows so much memory when it happens all at once. So I somehow cheated, as I only needed to print the result one line after another, without needing to store the computation result as a whole.
Back to the example, suppose I want to change the requirement a bit, and print all the transformed data to stdout instead of calculating some meaningless sum.
db.from_sequence(range(int(1e7)), 500) \
.map(lambda x: (x, [random.random()] * 5)) \
.map(lambda x: (x[0], [item * random.random() for item in x[-1]])) \
.map(lambda x: {'id': x[0], 'value': dict(zip(('lorem', 'ipsum', 'dolor', 'sit', 'amet'), x[-1]))}) \
.fold(lambda _, item: print(json.dumps(item)),
lambda *_: None) \
.compute()
So if I really print the result of the computation, I would probably get a None. However, by cheating and abuse the .fold() call, the transformed object is printed to the screen, the code is not swallowing memory like crazy, then I consider myself a happy boy.
So I am quite happy with the result for now, as it is clearly a better alternative to shoehorning DataFrame to do things that it is not designed to. Hopefully the resulting code is easier to read too, though this is quite subjective (I am sure some people find my example code unreadable).
